

Linked Open Data как средство обогащения поисковых запросов
В последнее время всё больше организаций, особенно правительственных, публикуют данные о своей деятельности в открытом доступе. Так, Министерство образования и науки РФ опубликовало на своём сайте www.opendata.mon.gov.ru для скачивания 58 наборов данных о функционировании системы школьного образования, о подведомственных организациях и т.п.
С одной стороны, у всех желающих появилась возможность изучить деятельность Минобрнауки России. С другой, это не очень удобно, потому что данные нужно скачать, проанализировать формат их представления, сравнить их с информацией из других источников. К тому же сведения постоянно обновляются. Всё это, конечно, не очень технологично. Чтобы избавить исследователя от необходимости постоянно скачивать данные, некоторые организации не только публикуют их отдельные наборы, но и предоставляют сторонним приложениям возможность обращаться напрямую к информации через различные API.*
* Работа выполнена при поддержке РФФИ, грант 15-07-05265 А
В масштабах страны эта деятельность координируется на портале www.data.gov.ru/opendata, где ведётся сводный реестр открытых данных. До недавнего времени библиотеки и другие информационные институты не придавали большого значения публикации своих данных в виде открытых наборов. Возможно, считалось, что в библиотеках и так всё открыто. Действительно, работа над протоколом Z39.50 началась в семидесятых годах прошлого века, ещё до эпохи веб. Первая версия протокола OAI-PMH была представлена в 2001 г. Кажется, что библиотеки опередили всех остальных и им не о чем беспокоиться. Однако ключевое отличие всех вышеперечисленных технологий от требований сегодняшнего дня в том, что данные должны быть не только открытыми, но и связанными. Давайте разберёмся, что это такое.
Связанные открытые данные (Linked Open Data, LOD) — это опубликованные структурированные данные, каждый элемент которых имеет свой URI, представлен в виде Resource Description Framework (RDF, www.w3.org/RDF) и имеет связь с другими данными. Главное отличие LOD от обычных веб-cтраниц в том, что они предназначены не столько для прочтения человеком, сколько для обработки компьютерными программами. Попробуем на примере пояснить, что это такое.
Как известно, все формальные описания различных сущностей, присутствующих в «Википедии», были выгружены в RDF-базу DBPEDIA, также находящуюся в открытом доступе. Если мы посмотрим, например, на страницу о Юлии Латыниной в DBPEDIA (www.dbpedia.org/page/Yulia_Latynina), то обнаружим описание персоны и ссылку от поля dbo:birthPlace к объекту «Москва» (www.dbpedia.org/page/Moscow), что вполне понятно всем программам, в отличие от подхода «Википедии», в которой связи устанавливаются между HTML-страницами, а не объектами. Из этого описания программа делает вывод о том, что:
1) Латынина — персона (agent) — (rdf:type — foaf:Person, dbo:Agent);
2) окончила Литературный институт (dbp:almaMater — dbr:Maxim_Gorky_Literature_Institute);
3) автор книги «Инсайдер» (is dbp:author of — dbr:The_Insider_(Latynina_novel).
То, что «Инсайдер» — это книга, можно определить по описанию этого объекта в DBPEDIA (www.dbpedia.org/page/The_Insider_(Latynina_novel)). В нём указано, что тип этой сущности в соответствии с онтологией DBPEDIA — Written work и Book, приведены различные сведения об этой книге. В LOD все отношения между понятиями строятся в виде графов. В модели RDF они называются триплетами и состоят из субъекта, объекта и предиката (утверждения о каком-либо свойстве субъекта, рис. 1).
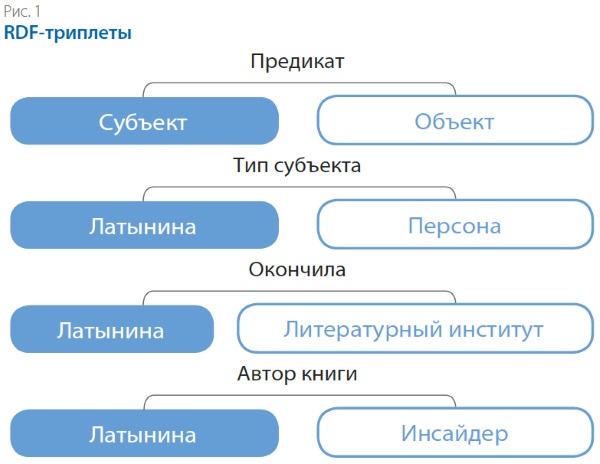
Связи между сущностями удобнее представлять в виде графа. На рис. 2 ниже представлен граф, составленный из таблицы данных, приведённых в «Википедии».
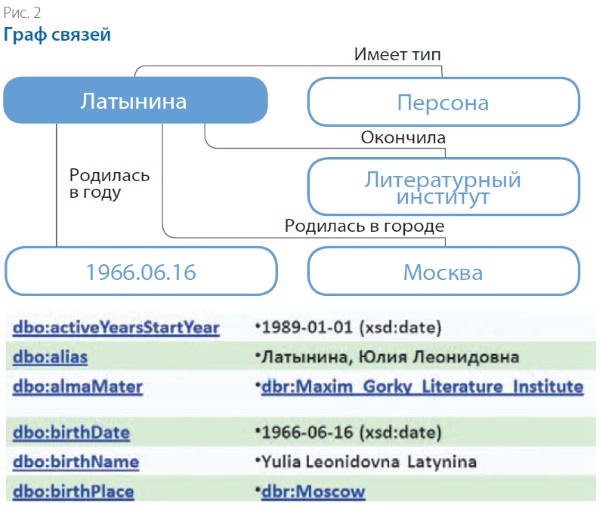
Преимущество представления связей в виде графов особенно очевидно, если продолжить выстраивать отношения между различными понятиями. Так, на рис. 3 видно, что одним из свойств персоны является место рождения. Значение этого свойства — «Москва», — в свою очередь, обладает множеством характеристик: географическими координатами, значимыми персонами. Таким образом, различные понятия оказываются связанными и становится возможным организовать навигацию по графу от понятия к понятию.
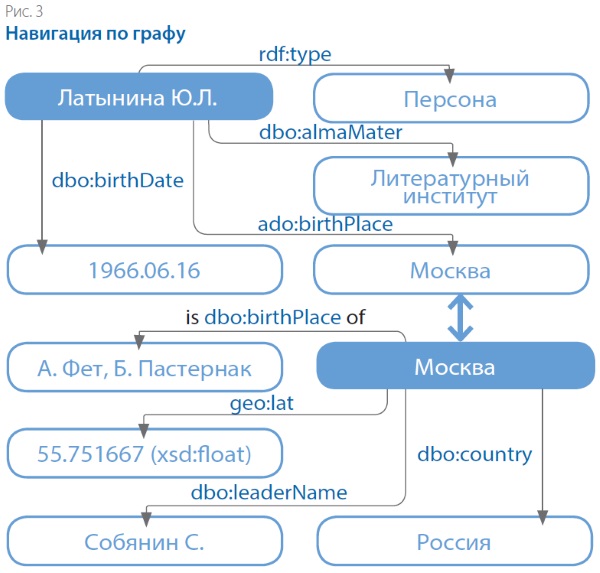
Принципиальной особенностью LOD является использование универсальных идентификаторов ресурса (Universal Resource Identifier, URI), однозначно определяющих место, куда можно обратиться за раскрытием понятия. Так, на рис. 4 вместо фамилии персоны указан её адрес в DBPEDIA, а вместо предиката «место рождения» — URI описания этого отношения в онтологии DBPEDIA.
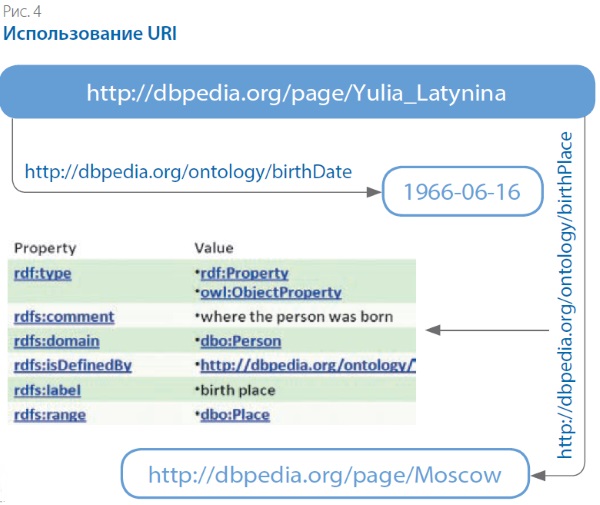
При этом нужно отметить, что связь понятий может происходить не только внутри одного графа (одной графической базы данных), но и между различными базами.
Возникает вопрос: а при чём тут библиотеки? Дело в том, что массив различных сведений, организованный в связанный граф, может помочь библиотекам в каталогизации и при поиске. В первую очередь нужно вспомнить про Virtual International Authority File (VIAF) www.viaf.org, в котором собрана информация о принятых формах написания имён авторов в разных странах и номер записи об этом авторе в системе ISNI (International Standard Name Identifier, www.isni.org, рис. 5).

Эта информация может помочь при каталогизации, поиске произведений авторов на языке, отличном от языка запроса, и т.п. Так, например, в сводном каталоге национальных и научных библиотек Европы, где собран массив библиографических описаний на разных языках, для расширения списка авторов используется VIAF и при вводе запроса «Пушкин» предлагается также поискать по Pushkin, Puskin и др. (рис. 6).

Схему взаимодействия пользователя с подобным сервисом можно представить следующим образом: программное обеспечение, получив запрос от пользователя, обращается на языке запросов к данным, представленным по модели RDF (SPARQL), в обогащающие сервисы (базы данных, содержащие дополнительную информацию). Например, если поиск ведётся в многоязычном массиве книг и в запросе присутствует фамилия автора, то запрос направляется в VIAF для получения всех форм написания автора. Если в метаданных в электронном каталоге отсутствуют данные о месте или дате рождения автора, а пользователю нужны только авторы, родившиеся в определённой стране и в определённый период времени, то можно обратиться в DBPEDIA и получить набор фамилий авторов, по которым искать документы уже в электронном каталоге. Поскольку мы ещё не встретили такого готового сервиса, то попробовали оценить, насколько сложным получается запрос в DBPEDIA для получения списка 10 авторов, написавших хотя бы одну книгу и родившихся в России после 1960 г., с выводом информации об их месте и дате рождения, краткой биографии, написанных книгах и с фотографией, если такие сведения имеются. Нужно сказать, что запрос получается совсем не сложным (он приведён ниже) и большую часть из него занимает определение используемых схем описания данных.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX dbpedia-owl: <http://dbpedia.org/ontology/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dbpedia-owl: <http://dbpedia.org/ontology/>
PREFIX dbpprop: <http://dbpedia.org/property/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT DISTINCT ?Name ?Title ?BirthPlace ?birthData
?authorPicture ?authorDescription WHERE
{
?TitleURL rdf:type dbpedia-owl:Book ;
dfs:label ?Title ;
dbo:author ?authorURL.
?authorURL foaf:name ?Name;
dbpedia-owl:abstract ?authorDescription ;
dbp:birthPlace ?BirthPlace.
OPTIONAL {
?authorURL foaf:depiction ?authorPicture.}
?authorURL dbpedia-owl:birthDate ?birthData.
FILTER(REGEX(STR(?BirthPlace), "Russia")).
FILTER (?birthData > "1960-01-01"^^xsd:date) .
FILTER langMatches( lang(?authorDescription), "RU" ) }
LIMIT 10
Отправив этот запрос в DBPEDIA, мы получили в ответ таблицу 1. Для экономии места мы приводим только выдержку из этой таблицы.

Авторы не преувеличивают степень достоверности данных в «Википедии» и соответственно в DBPEDIA. Тем не менее это очень удобный полигон для испытания различных технологий семантического веба — открытый, подробно размеченный и хорошо документированный.
При обогащении запросов нужно, разумеется, придерживаться принципа разумной меры. В противном случае мы рискуем «завалить» пользователя ненужными ему результатами. Мы, конечно, обеспечим ему полноту выдачи, но в большом количестве полученных результатов пользователь может и не дойти до необходимой ему информации. В общем, обогащение поисковых запросов средствами LOD очень полезный инструмент, если использовать его без фанатизма.
Хорошим примером обогащения результатов поиска может служить сайт www.kbresearch.nl/enrich [1]. Поиск в нём происходит обычным способом, но найденный в результате поиска текст «на лету» обрабатывается при помощи программного обеспечения GateAnnie (www.gate.ac.uk). С его помощью в тексте выделяются сущности, которые объединяются в классы и для них автоматически формируются запросы в DBPEDIA. В ответ на запрос в веб на тему «рыболовство в Греции» система выдала ряд страниц (используется API одной из поисковых систем), в тексте которых были найдены страны (Греция и Исландия) и виды рыб. При наведении курсора на найденное понятие всплывает окно с ссылкой на его страницу в DBPEDIA.
Ценность такого обогащения заключается в том, что нам не нужен заранее размеченный и подготовленный текст, работа происходит с обычной выдачей поисковых систем. Хотя, конечно, нельзя не отметить, что в настоящее время механизм автоматического выделения понятий далёк от совершенства.
Большое значение для библиотечной деятельности имеют различные нормативные данные в формате LOD. Библиотека Конгресса США опубликовала в виде LOD свои предметные рубрики, классификацию, тезаурусы и ряд других массивов (www.id.loc.gov). Начаты работы по публикации Danish Decimal Classification как Linked Open Data (www.opensource.dbc.dk/linked-data/dk5-linked-data). OCLC провёл исследование по представлению классификации Дьюи в виде LOD и даже опубликовал её на сайте www.dewey.info. К сожалению, в последнее время эта страница стала недоступна. Консорциум УДК представил более 2,4 тыс. индексов верхних уровней иерархии на 49 языках в виде LOD по адресу www.udcdata.info под лицензией Creative Commons. Центральная национальная библиотека Флоренции опубликовала свой тезаурус как LOD (www.thes.bncf.firenze.sbn.it/thes-dati_eng.htm). Эти данные можно скачать и использовать для загрузки в свои информационные системы.
Для того чтобы российская Библиотечно-библиографическая классификация (ББК) также могла быть встроена в семантический веб, мы начали работы по преобразованию ББК в LOD. В настоящее время существуют несколько версий ББК для библиотек различного типа. Для нашей работы мы решили использовать разделители из систематического каталога РГБ, содержащие реальные индексы, которые семантически богаче, поскольку включают в себя кроме индекса еще и типовые деления. Несколько лет назад в рамках работ по ретроконверсии весь систематический каталог был оцифрован и разделители из систематического каталога были распознаны [2]. Массив разделителей имел следующий вид.
Е Биологические науки
Е.а/я Биологические науки — Общий раздел
Е.б Биологические науки — Общий раздел — Руководящие и законодательные материалы СССР, Российской Федерации
………………………….
Е.в01 Биологические науки — Общий раздел — Философские вопросы. Методология — Предмет и задачи биологии
Е.в1 Биологические науки — Общий раздел — Философские вопросы. Методология — Философское значение законов, понятий, теорий биологии (а также отдельные философские понятия в биологии)
Самыми ценными в этом массиве были цепочки словесных формулировок каждого индекса, по которым мы смогли формализовать иерархию понятий. Так, например, рубрика Е991.780.551-73 имеет следующую словесную формулировку.
Биологические науки — Физиология, биофизика и биохимия животных и человека — Физиология, биофизика и биохимия функциональных систем, органов и процессов — Физиология, биофизика и биохимия нервной системы и органов чувств — Физиология, биофизика и биохимия нервной системы — Центральная нервная система — Кора головного мозга. Высшая нервная деятельность — Кора головного мозга — Возбуждение и торможение в коре — Сон и гипноз. Зимняя спячка — Сон — Физиология, биофизика и биохимия — Физиология.
Далее в качестве примера мы будем рассматривать раздел Е691.82, который занимает следующее место в ББК.
Е Биологические науки
Е6 Биологические науки — Зоология
Е69 Биологические науки — Зоология — Систематика животных. Специальные зоологические науки
Е691.82 Биологические науки — Зоология — Систематика животных. Специальные зоологические науки — Invertebrata. Беспозвоночные. Зоология беспозвоночных — Arthropoda. Членистоногие — Arachnoidea. Паукообразные. Арахнология
Е691.821 S corpionoidea. Скорпионы
Е691.822 Pedipalpi. Жгутоногие
Е691.823 Palpigradi. Пальпиграды
Е691.824 Pseudoscorpionidea. Лжескорпионы
……………………………
Е691.828 A carina. Клещи. Акарология
На начальном этапе работы мы решили выбрать не очень сложную схему описания рубрик, которая в первом приближении отвечала нашим задачам. Мы выбрали ряд отношений, рекомендуемых в модели Simple Knowledge Organization System (SKOS, www.w3.org/2004/02/skos).
skos:notation — код рубрики;
skos:prefLabel — наименование рубрики;
skos:narrower — нижестоящее понятие;
skos:broader — вышестоящее понятие.
Поскольку существующий индекс ББК не годится для автоматического построения иерархии, при разборе массива индексов мы ввели для каждого из них в соответствии с местом в массиве его позицию в иерархии. В нашей схеме этот элемент заносился в поле <rdfs:label>. После конвертирования в RDF вышеприведённый массив выглядел таким образом (верхний заголовок XML-файла опущен).
<rdf:Description rdf:about="http://oiks.rsl.ru/bbk/record.cgi?id=6.7.9.3.25.8">
<rdf:type rdf:resource="http://www.w3.org/2004/02/skos/core#Concept"/>
<skos:notation>Е691.82</skos:notation>
<skos:prefLabelxml:lang="ru">Arachnoidea. Паукообразные. Арахнология</skos:prefLabel>
<rdfs:label>6.7.9.3.25.8</rdfs:label>
<skos:narrower rdf:resource="http://oiks.rsl.ru/bbk/record.cgi?id=6.7.9.3.25.8.1" />
<skos:narrower rdf:resource="http://oiks.rsl.ru/bbk/record.cgi?id=6.7.9.3.25.8.2" />
……………………………………………
<skos:narrower rdf:resource="http://oiks.rsl.ru/bbk/record.cgi?id=6.7.9.3.25.8.11" />
<skos:broader rdf:resource="http://oiks.rsl.ru/bbk/record.cgi?id=6.7.9.3.25" />
</rdf:Description>
Для работы нам нужно было загрузить полученный RDF-файл в семантическое хранилище для последующего манипулирования им с помощью SPARQL-запросов. Изучив опыт Д.А. Малахова в выборе программного обеспечения [3], мы решили, что оптимальным решением для нашей задачи будет использование Virtuoso Universal Server, разработанного компанией OpenLink Software (www.virtuoso.openlinksw.com), сочетающего простоту установки и достаточную функциональность.
Действительно, мы установили Virtuoso Universal Server на сервере в РГБ по адресу www.oiks.rsl.ru:8890/sparql безо всяких проблем и загрузили туда опытный массив данных. Мы изначально рассчитывали, что хотим сделать сервис, позволяющий обслуживать SPARQL-запросы, а не просто разместить файл в формате RDF. По нашим представлениям, использование этого массива возможно в соответствии со следующими сценариями.
Обогащение библиографического описания. Предположим, что у нас есть книга с проставленным индексом ББК «Е691.82…». Чтобы получить ключевые слова для описания этой книги, можно использовать словесные наименования рубрик ББК этого уровня и любого количества нижестоящих уровней. Для такого определения нужно просто направить запрос на языке SPARQL в нашу базу. В описываемом случае мы запросили один нижестоящий уровень (рис. 7).
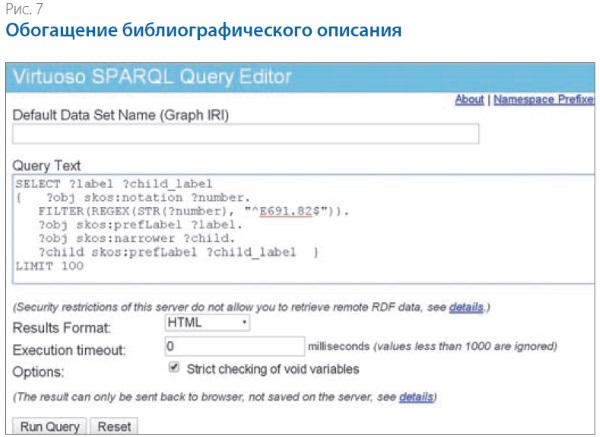
В результате мы получим наименование рубрики Е691.82 и список наименований одного нижестоящего уровня.

Точно такой же результат мы получим, если будем искать не по индексу ББК, а по слову из формулировки наименования рубрики (ниже приведён такой запрос).
SELECT ?label ?child_label
{ ?obj skos:prefLabel ?label.
FILTER(REGEX(STR(?label), "Паукообразные")).
?obj skos:narrower ?child.
?child skos:prefLabel ?child_label }
LIMIT 100
Другим сценарием является обогащение запроса (табл. 2).
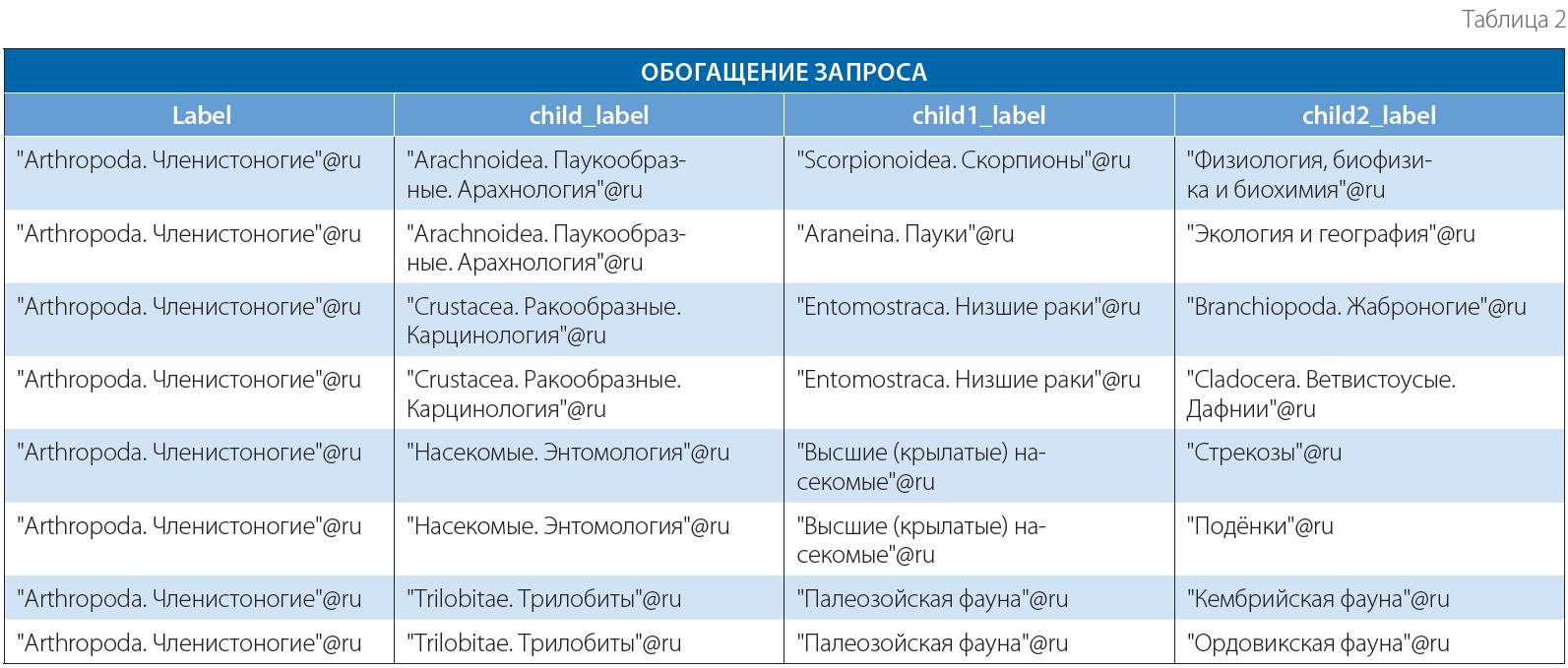
Предположим, что пользователь хочет найти все документы по паукообразным. Если он просто введёт в поисковую строку термин «паукообразные», то получит только те документы, в которых присутствует именно это слово. Следует обратить внимание на то, что речь идёт не только об электронном каталоге библиотек, но и обо всех поисковых сервисах, таких как «Яндекс», Google и т.п. В каких-то документах, посвящённых, например, фалангам, не будет слова «паукообразные», поскольку автор сочтёт совершенно очевидным то, что фаланги относятся к паукообразным, и не упомянет этого в тексте. Для того чтобы обогатить запрос наименованиями конкретных представителей паукообразных, нужно добавить наименования всех стоящих ниже на одно деление рубрик через оператор «или» (клещи, сенокосцы, скорпионы и т.п.). В некоторых случаях, возможно, лучше добавить наименования всех нижестоящих рубрик всех уровней. Например, если кто-то ищет по термину «членистоногие», то для наиболее полного поиска можно добавить в запрос через оператор «или» следующие термины: «паукообразные», «трилобиты», «ракообразные», «скорпионы», «дафнии» т.п.
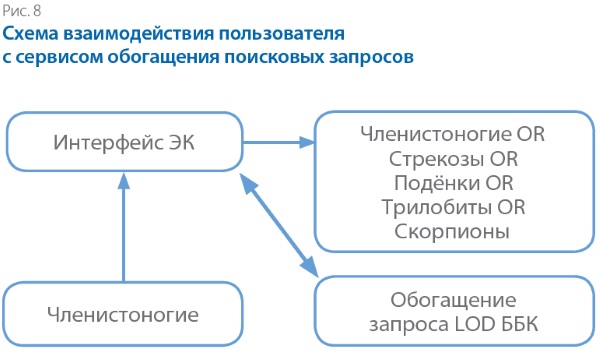
На рис. 8 приведена схема взаимодействия пользователя с сервисом обогащения поисковых запросов.
Ответы на запрос можно получать в различном виде. В Virtuozo предусмотрена возможность получения ответа в HTML, JSON RDF/XML и др. В настоящее время система находится на стадии разработки. Мы сделали прототип, загрузили в систему несколько разделов ББК и продолжаем готовить к загрузке остальные разделы.
К сожалению, в настоящее время только немногие библиотеки России начали работу в области открытых связанных данных. Авторы надеются, что данная статья привлечёт внимание широкой общественности к возможностям этого подхода и количество открытых наборов данных и SPARQL endpoint начнёт увеличиваться.
Используемаялитература
1. Fafalios P., Tzitzikas Y. — X-ENS: Semantic Enrichment of Web Search Results at Real-Time /SIGIR’13, 2013. — Режим доступа http://62.217.127.118/x-ens.
2. Лаврёнова О.А. Возможности пользователя при поиске информации в электронных библиотеках, или «Витязь на распутье» / Библиотековедение. — 2013. — № 3. — С. 43–52.
3. Малахов Д.А., Серебряков В.А., Теймуразов К.Б., Шорин О.Н. Интеграция библиографических данных в Linked Open Data // Труды 16-й Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». — RCDL–2014, Дубна, Россия, 13–16 октября 2014 г.
Авторы Михаил Ефремович Шварцман, начальник отдела исследования компьютерных систем Российской государственной библиотеки; Олег Павлович Найдин, ведущий программист отдела исследования компьютерных систем Российской государственной библиотеки
Рубрика: Инновационные технологии
Год: 2015
Месяц: Декабрь
Теги: Михаил Шварцман Олег Найдин